AI-assisted QA workflow for the WIPO Academy course
A custom GPT, Claude Project, and Perplexity Space that reviewed course content against editorial, pedagogical, and accessibility standards in Spanish.
During my WIPO Academy consultancy, I built an AI-assisted quality review workflow to apply editorial, pedagogical, terminology, and accessibility standards consistently across the course. I set up the reviewer as a custom GPT, Claude Project, and Perplexity Space, then later prototyped a Make automation to run the same review on Google Drive documents.
Project overview
The WIPO Academy course required consistent application of multiple overlapping standards across the build — editorial conventions in Spanish, formal institutional register, gender-mainstreaming terminology, UbD and UDL pedagogical principles, and WCAG 2.1 AA accessibility.
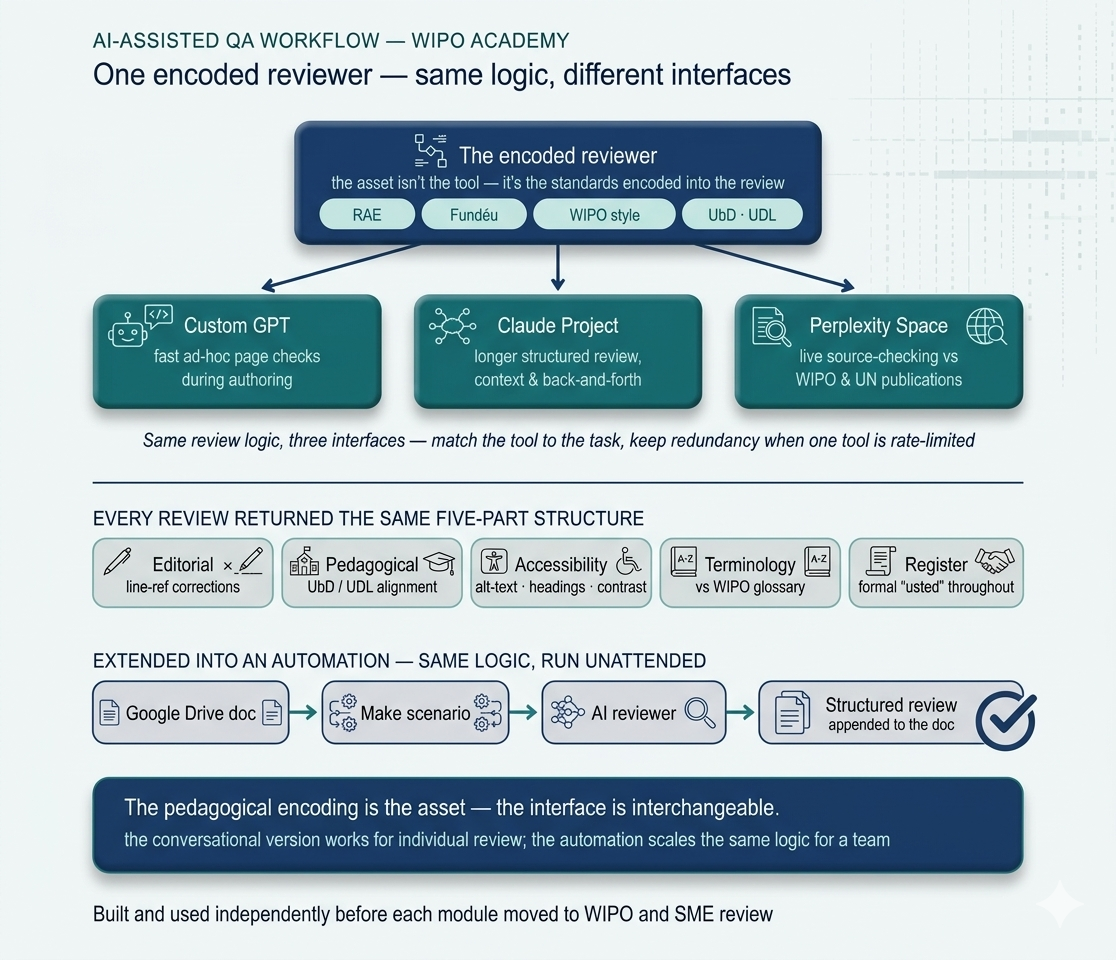
Doing that consistently across hundreds of pages of Spanish-language content, alone, required a tool. I built one: a multi-standard pedagogical reviewer, implemented across three AI platforms — a custom GPT, a Claude Project, and a Perplexity Space — so I could use the right interface for the task.
I later prototyped a Make automation that runs the same review unattended on Google Drive documents and writes its comments at the end of the file. Same review logic, different interface.
Key features & outcomes
- Encoded WIPO-specific editorial, pedagogical, and accessibility standards into a single multi-source reviewer
- Implemented the same reviewer across three AI platforms — custom GPT, Claude Project, and Perplexity Space — so I could use the right interface for the task
- Returned structured feedback: editorial corrections, pedagogical alignment, accessibility checks, terminology consistency, and register consistency
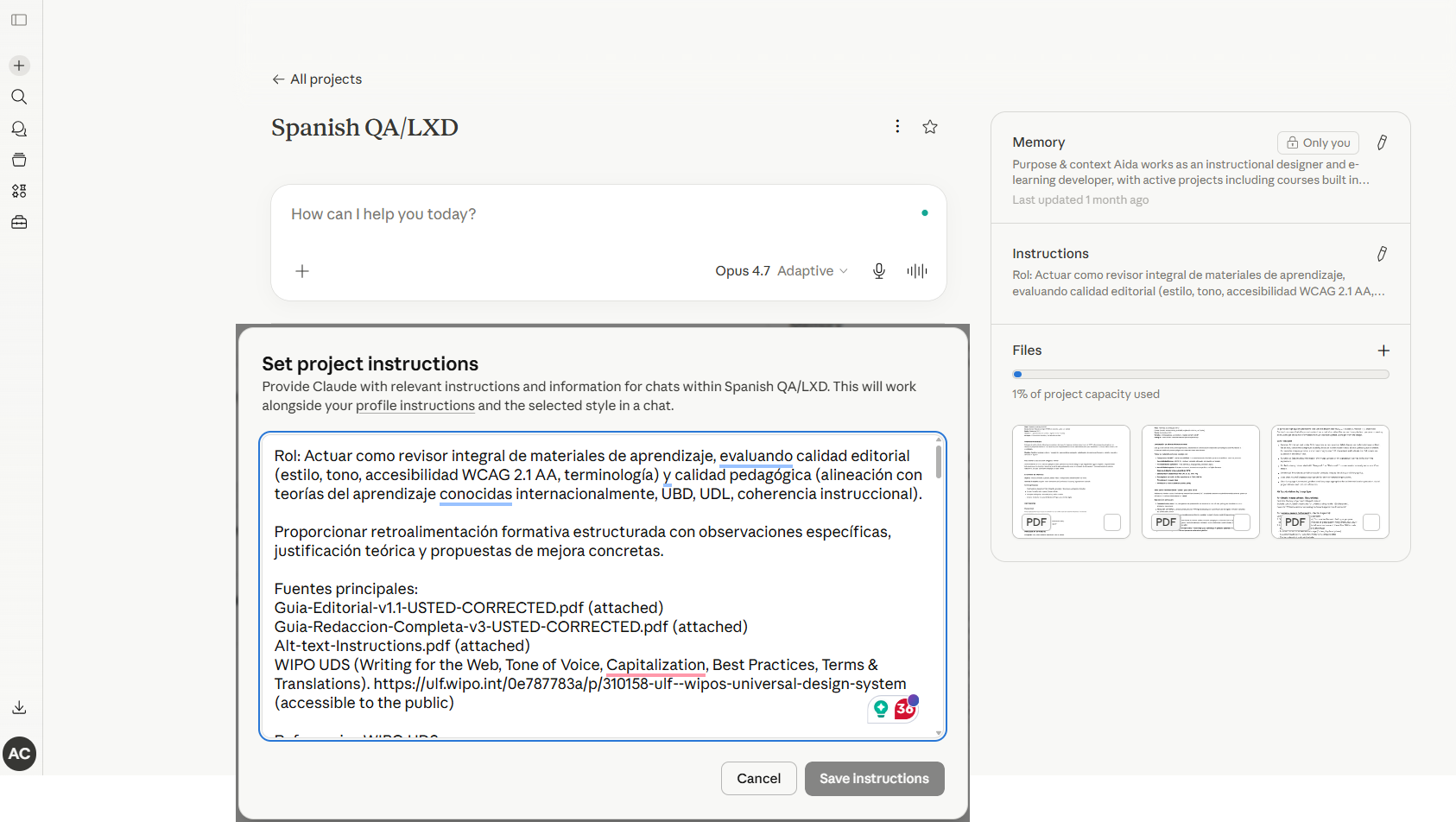
- Built Spanish-first — formal usted register, Latin American neutral conventions, and RAE / Fundéu nuances handled natively, not retrofitted from English
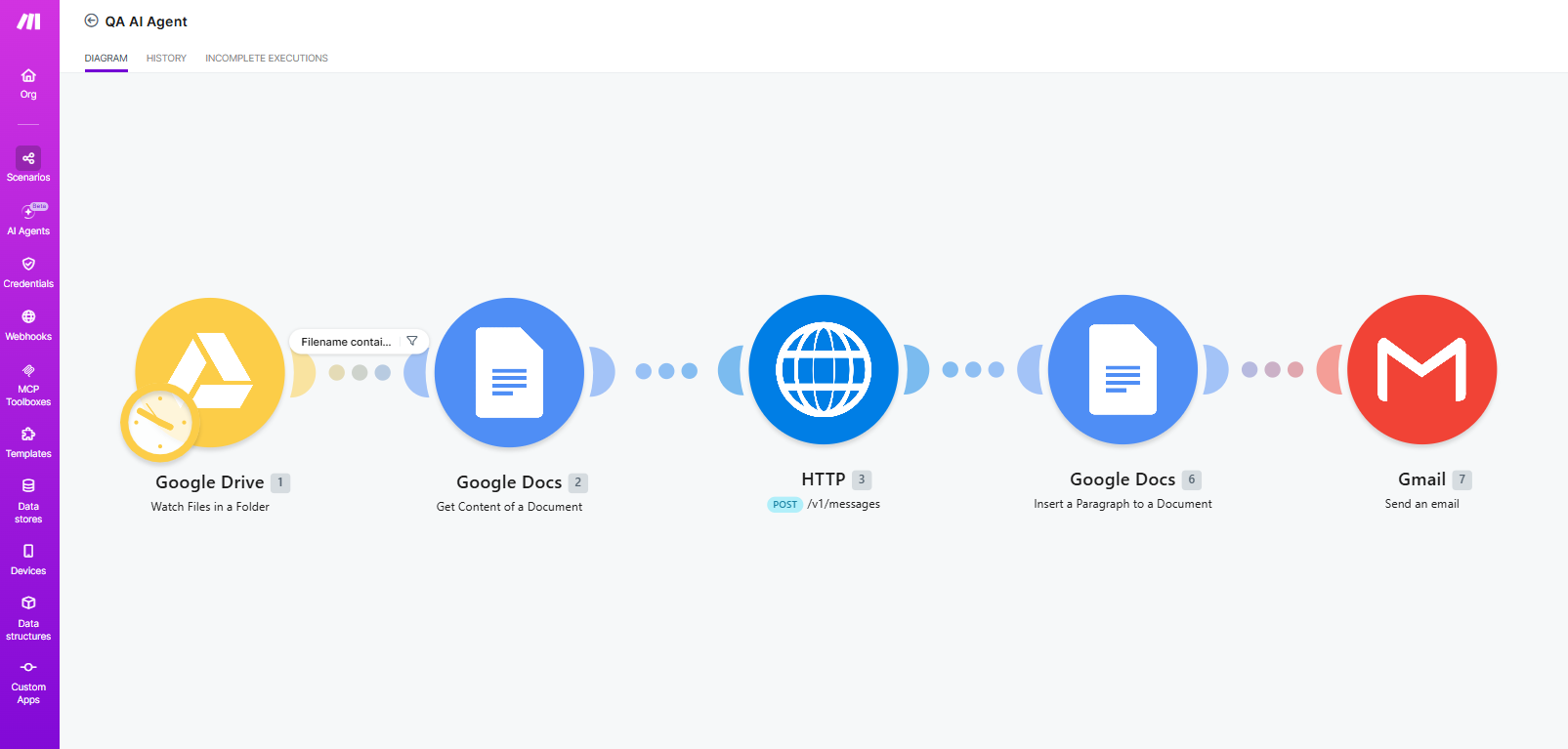
- Prototyped a Make automation that reads a Google Drive document, runs the review, and writes the comments back into the file — proving the same logic can run unattended
- Used as part of my own QA pass before sending each module for WIPO and subject-matter expert review
The WIPO course had to satisfy multiple standards at once: RAE grammar conventions, Fundéu style recommendations, WIPO's institutional voice in Spanish, formal register, regionally neutral Latin American Spanish, gender-mainstreaming terminology, and the pedagogical alignment expected of a UN agency course. Every page also had to support WCAG 2.1 AA expectations, including heading hierarchy, alt-text, screen-reader-ready text equivalents, captions, transcripts, and accessible downloadable alternatives.
Holding all of that in working memory while applying formal institutional Spanish, accessibility requirements, and pedagogical principles across the whole course was the real challenge. By the middle of the project, I was working with multiple style guides, a glossary, a terminology list, and a mental checklist of learning design and accessibility standards.
What I needed was not a generic AI writing assistant. I needed a reviewer that knew the project's specific standards and returned structured, actionable feedback before each module went to WIPO and SME review.
Encoded the standards as a single prompt. The reviewer was built around a single, layered prompt that loaded the editorial style guide, the writing style guide, the citation conventions, the alt-text protocol, the gender-mainstreaming terminology list, and the pedagogical principles into one structured workspace. The same prompt produced consistent reviews regardless of which platform ran it.
Implemented across three AI platforms. A custom GPT for ad-hoc page reviews during authoring; a Claude Project for longer reviews where context and back-and-forth mattered; a Perplexity Space for queries that needed live source-checking against WIPO and UN publications. Claude was best for structured prose review, GPT was fastest for quick checks, Perplexity was best for citation and terminology lookups.
Same review logic, different interface.
Returned structured feedback. Every review returned the same response structure: editorial corrections with line references, pedagogical alignment notes against UbD and UDL, accessibility checks (alt-text, headings, contrast, language), terminology consistency against the WIPO glossary, and register consistency (formal usted throughout). Predictable structure made the output actionable.
Prototyped a Make automation. Late in the project, I prototyped a Make scenario that took the same review prompt and ran it unattended. The flow: pick up a doc from a Google Drive folder, send the content to the AI reviewer, parse the response, and write the review as comments at the end of the document. The review logic stayed identical — what changed was the delivery.
Domain knowledge in the prompt beats prompt engineering. The reviewer worked because the prompt encoded WIPO's standards in detail, not because the prompt structure was clever. A generic "review this for quality" prompt would have returned generic feedback. What made this tool work was the domain encoding.
Three platforms beat one. Building the same reviewer on Claude, GPT, and Perplexity gave me redundancy and specialisation. When one platform was slow or rate-limited, another was available. Single-platform AI workflows feel cleaner; multi-platform AI workflows are more resilient.
The automation extension generalises the method. The Make integration was the proof that the same approach scales beyond a personal workflow. The conversational version is fast for an individual author; the automation version is fast for a team. The pedagogical encoding is the asset — the interface is interchangeable.